




فایل Robots.txt چیست؟ ساخت فایل robots و دستورات اصلی آن
همانطورکه در مقاله موتور جستجو چیست؟ هم اشاره کردیم، موتورهای جستجو مسئول کراولینگ و ایندکس صفحات وبسایت های موجود در وب هستند. اینجاست که ربات ها وارد عمل می شوند. با اینکه ربات های خوب و بد زیادی داریم ولی ربات هایی که کارهای مربوط به خزیدن و ایندکس صفحات وب را انجام می دهند، جزو ربات های خوب هستند و صاحبان وبسایت با استفاده از فایل Robots.txt می توانند نحوه رفتار این ربات ها را تعیین کنند.
فایل Robots.txt یک فایل متنی حاوی دستورالعمل های لازم برای مسدودسازی برخی از صفحات و محتوای وبسایت است که دوست ندارید توسط ربات های خزنده خزیده و ایندکس شوند. ایجاد و استفاده از یک فایل ربات بهینه، با تغییرات مثبت در عملکرد سئو سایت همراه خواهد بود.
در واقع، فایل Robots.txt یکی از فایل های متنی موجود در دایرکتوری ریشه وبسایت است که به خزنده های وب می گوید کدام صفحات اجازه دسترسی دارند و کدام صفحات برای نمایش عمومی نیستند. این فایل اهمیت زیادی در کنترل رفتار ربات های موتورجستجو و همچنین، ارائه یک نمای کلی از URL های موجود در وبسایت دارد که اگر آن را به درستی پیکربندی کنید، مطمئناً شاهد نتایج مثبت آن در سئو سایت خود خواهید شد.
اگر هیچ آشنایی اولیه ای با فایل robots ندارید و دوست دارید تمام اطلاعات لازم برای استفاده درست از آن را به دست بیاورید، ما در کنار شما هستیم.
اگر با خرید سرور مجازی، زیرساخت قدرتمندی برای راه اندازی وبسایت و هندل کردن درخواست ها و ترافیک زیاد آماده کرده اید و الان هم به فکر مدیریت و کنترل نحوه رفتار خزنده وب هستید، این مقاله به شما کمک می کند که ایده های بهتری در زمینه تنظیم و پیکربندی درست قوانین فایل Robots.txt به دست بیاورید و هر چه سریع تر برای بهبود عملکرد وبسایت خود در نتایج جستجو دست به کار شوید.
پس بیایید شروع کنیم:
فایل Robots.txt چیست؟ 
هر وبسایت، حاوی صفحاتی است که هر کدام مسئول ارائه محتوا یا سرویس های خاصی هستند. در حالت ایده آل، اگر بخواهیم تمام صفحات وبسایت را برای نمایش عمومی آماده کنیم، دیگر نیازی نیست که رفتار ربات های موتور جستجو را کنترل کنیم چون آنها باید بتوانند به تمام صفحات دسترسی پیدا کرده و آنها را ایندکس کنند که این هم به نوبه خود می تواند باعث ایجاد اختلال و هرج و مرج شود.
اما ما در یک دنیای کامل و بی نقص زندگی نمی کنیم. بسیاری از سایت ها دارای تله های عنکبوت، مشکلات canonical URL و صفحه های خصوصی هستند که باید از دید موتورهای جستجو دور بمانند.
اینجاست که فایل robots وارد صحنه می شود.
بیایید با استفاده از یک مثال، جایگاه فایل ربات در وبسایت را توضیح دهیم:
فرض کنید برای اولین بار وارد سازمان امور مالیاتی شده اید و هیچ بخش و اتاقی را نمی شناسید. اگر بخواهید تک تک اتاق ها را بررسی کنید تا اینکه در نهایت با فضای آن آشنا شوید، هم خودتان خسته می شوید و هم اینکه اگر همه کاربران مثل شما این کار را انجام دهند، سازمان هم دچار هرج و مرج می شود.
اما به سمت راست خود نگاه می کنید و مامور باجه اطلاعاتی را می بینید که آماده ارائه اطلاعات لازم در مورد لوکیشن و وضعیت بخش های مختلف سازمان است. اینکه چه اتاق هایی در دسترس مشتری هستند و قابل مراجعه هستند و چه اتاق هایی برای استفاده خصوصی هستند و دسترسی به آنها ممکن نیست.
بله، فایل ربات ها هم چنین نقشی را در سایت شما ایفا می کند. ربات هایی که وارد وبسایت شما می شود، اول فایل Robots.txt را بررسی می کنند تا نحوه رفتار خود را بر اساس قوانین و دستورات موجود در آن تنظیم کنند.
ولی فایل ربات چیست و شامل چه اطلاعاتی است؟
فایل robots یک فایل متنی است که مدیران وبسایت از آن برای تعریف رفتار ربات های موتور جستجو استفاده می کنند. در واقع، این فایل بخشی از پروتکل محرومیت ربات ها (REP) است که استانداردهای لازم برای نحوه کراولینگ ربات ها در وب، دسترسی و ایندکس به صفحات و نمایش آنها به کاربران را تنظیم می کند.
در عمل، فایل های ربات به ربات های خزنده وب نشان می دهند که کدام بخش های وبسایت برای خزش آماده هستند و کدام بخش ها نباید خزیده شوند.
این فایل در دایرکتوری ریشه سایت قرار می گیرد و ربات های اکثر موتورهای جستجوی اصلی مثل گوگل، بینگ و یاهو، قبل از اینکه یک صفحه ای از دامنه را درخواست کنند، اول این فایل را بررسی می کنند و به قوانین و دستوراتی که در آن لحاظ شده است، احترام می گذارند.
پس اگر می خواهید از بخش های خاصی از وبسایت خود محافظت کنید تا در دسترس خزنده ها و در نتیجه، کاربران عمومی قرار نگیرد، می توانید از فایل Robots.txt کمک بگیرید.
این فایل حاوی دستورالعمل هایی در مورد صفحات، دایرکتوری ها یا سایر فایل های موجود در وبسایت است که باید یا نباید کراول و ایندکس شوند. این دستورالعمل ها باید طوری تنظیم شوند که ربات های خزنده همه موتورهای جستجو را در بر بگیرند تا همه آنها رفتار مشابهی را از خود نشان دهند.
چرا فایل Robots.txt مهم است؟
با اینکه فایل robots یک بخش اجباری از وبسایت شما نیست و شما به اختیار خود می توانید ربات های وب را برای هر مدل کراولینگ و ایندکس آزاد بگذارید ولی استفاده از یک فایل ربات درست، نقش مهمی در بهینه سازی عملکرد وبسایت شما دارد. بیایید این بهینه سازی را از ۲ جهت مختلف بررسی کنیم:
بهینه سازی بودجه خزیدن سایت
ربات های موتورهای جستجو منابع محدودی دارند و تعداد URL هایی که می توانند برای یک وبسایت بخزند و ایندکس کنند، محدود است. این تعداد به فاکتورهایی مثل اندازه و بک لینک ها بستگی دارد ولی در حالت کلی محدود است و اگر تعداد صفحات وبسایت شما بیشتر از بودجه خزیدن باشند، این امکان وجود دارد بعضی از صفحات مهم و باارزش وبسایت شما ایندکس نشوند و جایی در بین نتایج جستجوی کاربران نداشته باشند.
اگر وبسایت شما کوچک است و تعداد صفحات کمتری دارد، شاید این فاکتور برای شما زیاد اهمیت نداشته باشد، اما هر مدیر وبسایت بزرگی می داند که استفاده بهینه از منابع ربات های موتور جستجو چقد مهم و حیاتی است.
در حال کلی، اگر با استفاده از فایل ربات ها بتوانید صفحات غیرضروری و بی اهمیت را به عنوان صفحه Disallow تنظیم کنید، در واقع از بودجه ای که برای شما اختصاص یافته است، به صورت بهینه تر استفاده می کنید.
مسدودسازی صفحات تکراری و خصوصی
حتماً نیازی نیست که تمام صفحات وبسایت شما ایندکس شوند. حتی صفحاتی که برای اعضای سایت و کاربران ویژه هستند یا صفحاتی که محتوای تکراری دارند، اصولاً نباید ایندکس شوند.
با استفاده از فایل robots.txt می توانید از خزش و ایندکس صفحات تکراری، خصوصی، بی کیفیت و … جلوگیری کنید و از این طریق، کیفیت و عملکرد سایت خود را بهینه کنید.
همچنین، اگر به فکر جلوگیری از ایندکس شدن فایل های رسانه ای مثل تصویر و PDF هستید و با استفاده از دستورات متا به نتایج خوبی نرسیده اید، با خیال راحت می توانید به robots.txt اعتماد کنید.
در حالت کلی اگر به فکر کاهش بار و کنترل دسترسی موتورهای جستجو هستید و دوست دارید در کنار استفاده بهینه از بودجه کراولینگ، اطلاعات و صفحات خاص وبسایت خود از دید عموم دور نگه دارید، حتماً باید به فکر ایجاد و تنظیم یک فایل Robots.txt باشید.
فایل ربات چگونه کار می کند؟
کار اصلی فایل robots این است که به ربات های موتور جستجویی مثل Googlebot بگوید کدام URLها قابل خزش هستند و مهم تر از آن، کدام URLها را باید نادیده بگیرند.
با توجه به این که موتورهای جستجو دو هدف اصلی دارند:
۱. خزیدن در وب و کشف محتوای جدید
۲. ایندکس و ارائه محتوا به کاربران
فایل ربات حکم یک میزبان اصلی را دارد که در را برای موتورهای جستجو باز می کند. به این صورت که یک ربات خزنده موقع مراجعه به یک وبسایت، قبل از هر کاری محتویات فایل ربات را بررسی می کند.
ساختار این فایل بسیار ساده و قابل درک است. بلوک های که در این فایل وجود دارند از ۲ بخش “شناسه کاربر” و “دستور العمل” تشکیل شده است.
این قالب قوانین برگرفته از پروتکل Robots Exclusion Protocol است. در واقع، این پروتکل به موتورهای جستجو می گوید که از کدام صفحات و منابع دوری کنند. دقیقاً همان کاری که فایل ربات انجام می دهد و به همین خاطر، دستور العمل های فرمت شده برای این پروتکل در داخل فایل Robots.txt گنجانده شده است.
با اینکه در قسمت دستورات، به طور مفصل در این مورد صحبت می کنیم ولی بیایید یک مثال ساده از فرمت این پروتکل را بررسی کنیم:
بخش شناسه کاربر با متغیر User-Agent و بخش دستورالعمل هم با دستوراتی مثل disallow مشخص می شود.
حالا اگر بخواهیم به گوگل بات بگوییم که نباید آدرس https://www.example.com/page را کراول کند، باید تکه کد زیر را در فایل robots بنویسیم:
User-agent: googlebot
Disallow: https://www.example.com/pageنمای بالا که در دو خط جدا نوشته می شود، برای افزایش خوانایی قانون است و می توانید این قانون را به صورت زیر هم بنویسید:
User-agent: googlebot Disallow: https://www.example.com/pageاین دستور به خزنده گوگل می گوید که صفحه موردنظر را باز نکند ولی اگر فقط به کاربر یعنی googlebot اکتفا کنید، تغییری در رفتار موتورهای جستجوی دیگری مثل bing اتفاق نمی افتد، پس بهتر است این فیلتر را برای تمام موتورهای جستجو اعمال کنید:
User-agent: googlebot
Disallow: https://www.example.com/page
User-agent: Bingbot
Disallow: https://www.example.com/page
User-agent: Yahoobot
Disallow: https://www.example.com/pageایده هوشمندانه تر هم این این است که به جای وارد کردن تک تک این ربات ها از وایلد کارت (*) استفاده کنید تا این قانون برای تمام ربات ها اعمال شود:
User-agent: *
Disallow: https://www/example.com/pageاگر خواستید می توانید به جای لینک صفحه، فایل یا فولدرهای موردنظر را از دسترس خزنده خارج کنید:
User-agent: *
Disallow: /folder/subfolder/page.html
Disallow: /subfolder2/
Disallow: /folder2/اما پروتکل دیگری به اسم پروتکل Sitemaps هم وجود دارد که برای فایل robots استفاده می شود. کاربرد اصلی این پروتکل، ارائه نقشه سایت به خزنده های وب است. به این ترتیب خزنده ها به کمک سایت مپ متوجه می شوند که باید کدام صفحات را بخزند و در نتیجه، احتمال از دست دادن صفحات مهم کمتر می شود.
در حالت کلی، فایل نقشه سایت با فرمت xml است و اگر فایل sitemap.xml را ایجاد کرده اید، می توانید آن را به صورت زیر در فایل ربات قرار دهید تا موتورهای جستجو به آن فایل دسترسی پیدا کرده و به کمک آن، صفحات و اطلاعات مربوط به آنها را شناسایی کنند.
Sitemap: https://example.com/sitemap.xmlدر کل، ایده این پروتکل ها برای پیاده سازی قوانین، خیلی ساده است و با کسب یک سری اطلاعات پایه در این زمینه، می توانید یک فایل ربات دقیق و کارآمد ایجاد کنید.
توجه! با اینکه می توانید هر دستورالعمل دلخواهی را در فایل ربات لحاظ کنید ولی هیچ تضمینی برای اجرای آن توسط تمام ربات ها وجود ندارد. کافیست این فایل را به عنوان یک کد رفتاری در نظر بگیرید که ربات های خوب ( مثل ربات های موتور جستجو) به آن احترام می گذارند و از آن پیروی می کنند ولی ربات های بد ( مثل ربات های اسپم) آنها را نادیده می گیرند.
ساختار و دستورات فایل متنی robots.txt
فایل ربات از قانون هایی تشکیل می شود که هر قانون هم به دو بخش user-agent و دستورالعمل تقسیم می شود.
user-agent برای تعیین ربات وب استفاده می شود( مثلاً Googlebot)
این کاربر می تواند اسم انواع ربات های جستجو را به عنوان مقدار قبول کند و دستورات لازم را برای آنها اعمال کند.
اگر هم می خواهید دستور یا قانون موردنظر را برای همه ربات های فعال در اینترنت اعمال کنید، می توانید * را به عنوان user-agent تعیین کنید.
دستوراتی که در خط بعدی اسم ربات (user-agent) قرار می گیرند، مشخص کننده رفتار ربات در مقابل لینک، فولدر یا فایل موردنظر هستند.
حالا نوبت به بررسی این دستورات می رسد که در ادامه سعی می کنیم با استفاده از مثال های عملی کاربرد و نحوه استفاده از آنها را توضیح دهیم:
دستور Disallow
همانطور که از اسم آن هم مشخص است، این دستور برای جلوگیری از دسترسی ربات خزنده به بخش موردنظر استفاده می شود. کاربرد این دستور با مثال های زیر بهتر مشخص می شود:
جلوگیری از دسترسی تمام ربات های موتورهای جستجو به کل سایت
User-agent: *
Disallow: /مسدود کردن یک فایل یا به اصطلاح یک صفحه برای گوگل بات
User-agent: Googlebot
Disallow: /learning/bots/bots1.htmlبلاک کردن فولدر تصاویر و تمام محتویات آن برای موتور جستجو بینگ و یاهو
User-agent: Bingbot
Disallow: /images/
User-agent: Yahoobot
Disallow: /images/اجازه دسترسی یا کراولینگ تمام صفحات به گوگل بات
User-agent: Googlebot
Disallow:جلوگیری از دسترسی تمام ربات ها به صفحاتی که با blog/ شروع می شوند. ( با کاراکتر *)
User-agent: *
Disallow: /blogمسدودسازی تمام URL های حاوی رشته autos برای تمام ربات ها
User-agent: *
Disallow: /*autosبلاک کردن تمام محتویات یا صفحات دارای پسوند autos. برای تمام ربات ها (با کاراکتر $)
User-agent: *
Disallow: *.autos$بلاک کردن فایل های pdf برای گوگل بات
User-agent: Googlebot
Disallow: /*. pdf$با استفاده از این تکنیک می توانید از خزش و ایندکس فایل های موردنظر خود مثل تصاویر، برنامه ها یا لاگ ها توسط ربات های موتورجستجو جلوگیری کنید.
Disallow: /*. doc$
Disallow: /*. jpg$دستور allow
این دستور، دقیقاً برعکس دستور disallow عمل می کند. به عنوان مثال، اگر قرار باشد از خزش و ایندکس تمام پست ها (blog/) به جز یک پست جلوگیری کنید، کافیست آن پست را در دستور allow لحاظ کنید.
User-agent: Googlebot
Disallow: /blog
Allow: /blog/example-postالبته توجه داشته باشید که از بین تمام موتورهای جستجو، فقط گوگل و بینگ از دستور allow پشتیبانی می کنند.
مسدود کردن کل سایت برای تمام ربات ها به جز گوگل بات
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /مسدود سازی تمام محتویات فولدر موردنظر به جز یک فایل برای تمام ربات ها
User-agent: *
Disallow: /folder/subfolder/
Allow: /folder/subfolder/page.htmlدستورالعمل Sitemap
با استفاده از این دستور می توانید فایل xml مربوط به نقشه سایت خود را در اختیار ربات های خزنده قرار دهید تا با بررسی آنها متوجه شوند که کدام صفحات وبسایت شما ارزش و اهمیت بیشتری دارند و می خواهید کراول و ایندکس شوند.
با اینکه این نقشه در ترتیب ایندکس صفحات توسط ربات ها تغییر ایجاد نمی کند ولی اگر یک نقشه سایت درست ایجاد کنید و آن را در فایل Robots.txt قرار دهید، اطمینان اینکه کراولرها موقع خزیدن وبسایت شما، چیزی را از دست نمی دهند خیلی بالاتر می رود.
برای اینکار کافیست نقشه یا نقشه های وبسایت خود به صورت زیر در فایل ربات قرار دهید تا تمام ربات ها قادر به مشاهده این نقشه ها باشند:
User-agent: *
Sitemap: https://yoursite.com.com/sitemap1.xml
Sitemap: https://yoursite.com.com/sitemap2.xmlدستور Crawl-Delay
این دستور برای تاخیر در عمل خزش استفاده می شود. در واقع، به خزنده ها دستور می دهد که بین درخواست های متوالی خود برای بارگذاری و خزیدن محتوای صفحات وبسایت چند ثانیه صبر کنند. هدف از این کار، کاهش بار سرور و جلوگیری از افت سرعت سایت است.
با اینکه، گوگل از این دستور پشتیبانی نمی کند ولی اگر موتورهای جستجوی دیگری مثل بینگ و یاندکس هم برای شما اهمیت دارند، می توانید این دستور را به صورت زیر در فایل ربات لحاظ کنید.
User-agent: *
Crawl-delay: 10دستور بالا باعث می شود که بین درخواست های متوالی ربات ها به وبسایت موردنظر، ۱۰ ثانیه وقفه بیافتد.
حالا که با دستورات اصلی robots آشنا شدیم، وقت آن است که یک فایل ربات عالی برای وبسایت خود ایجاد کنید.
نحوه ایجاد فایل متنی robots
اگر با مراجعه به آدرس زیر، فایل ربات وبسایت باز نمی شود، پس احتمالاً تا الان این فایل را ایجاد نکرده اید:
https://site-address.com/robots.txt
با طی مراحل زیر می توانید فایل ربات مخصوص وبسایت خود را ایجاد کنید:
۱. یک فایل متنی ایجاد کنید.
ادیتور متنی موردنظر مثلاً notepad را باز کنید و یک فایل متنی با اسم robots.txt ایجاد کنید.
مطمئن باشید که این فایل دقیقاً با اسم robots.txt ذخیره شده است و هیچ فایل هم اسم با این فایل در دایرکتوری ریشه سایت وجود ندارد.
۲. قوانین موردنظر را به فایل robots اضافه کنید.
طبق آموزش هایی که در بخش دستورات robots.txt ارائه دادیم، الان دیگر نوبت شماست که قوانین و دستورالعمل های مناسب وبسایت خود را ایجاد کنید و در این فایل قرار دهید.
فولدرها، url ها، فایل ها و هر محتوای دیگری که قرار است مطابق با دستورات allow و disallow مسدود شوند یا در دسترس عموم قرار بگیرند را مشخص کنید و سپس بلوک های قوانین مناسبی را برای آنها ایجاد کنید.
یک نمونه از قانون robots برای وبسایت:
User-agent: Googlebot
Disallow: /clients/
Disallow: /admin
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xmlتوجه داشته باشید که کراولرها این فایل را از بالا به پایین می خوانند و با اولین گروه های کاربری که در فایل قرار داده اید، مطابقت پیدا می کنند. پس سعی کنید در بلوک های اول قوانین اختصاصی برای ربات های موردنظر را پیاده سازی کنید و بعد سراغ * و قوانین مطابق با همه خزنده ها بروید.
۳. فایل Robots.txt را در دایرکتوری ریشه آپلود کنید.
بعد از اینکه قوانین موردنظر را در فایل ربات ها قرار دادید، وقت آن است که آن را در دایرکتوری ریشه سایت آپلود کنید تا در دسترس ربات های خزنده قرار بگیرد.
این بستگی به پلتفرم و نوع هاستینگ وبسایت شما دارد که فایل ربات را چگونه در وب سرور آپلود کنید.
۴. فایل ربات وبسایت خود را تست کنید.
بعد از اینکه این فایل را در سرور آپلود کردید، نوبت به بررسی وضعیت آن می رسد. برای این کار کافیست مرورگر خود را باز کنید و بعد از وارد کردن آدرس سایت خود، robots.txt را وارد کنید و اینتر را بزنید:
https://example.com/robots.txt
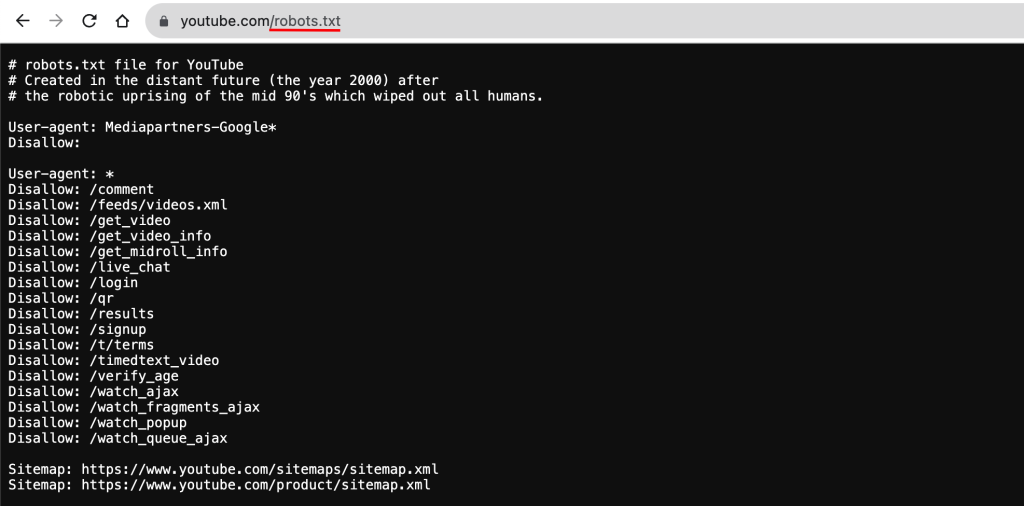
اگر محتوای فایل robots را می بینید، تبریک می گوییم شما با موفقیت از عهده این کار برآمدید.
البته اگر از گوگل سرچ کونسول استفاده می کنید، یک راه دیگر هم برای بررسی و تست فایل ربات دارید.
کافیست ابزار robots.txt Tester را اجرا کنید و بررسی کنید که فایل ربات شما به درستی کار می کند یا نه. 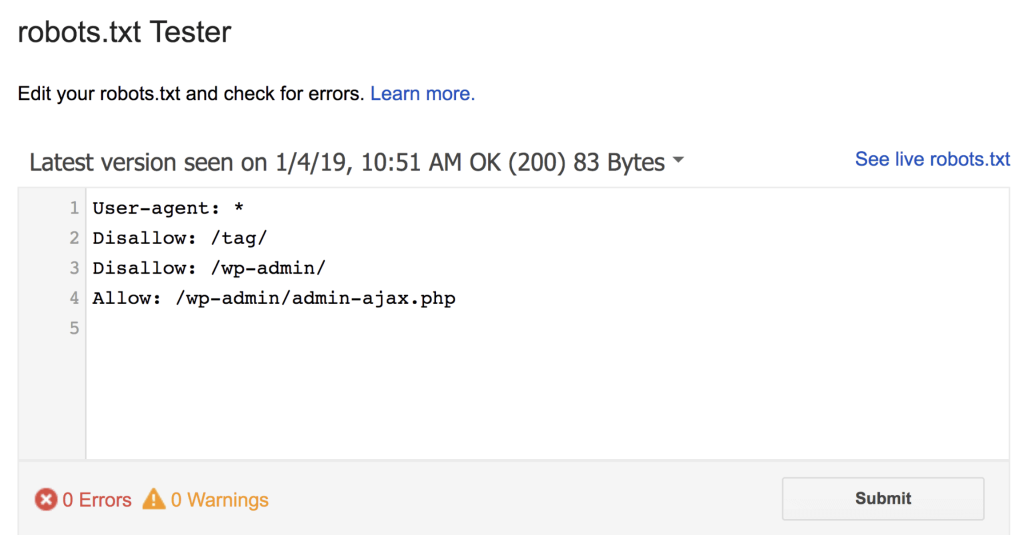
نقش فایل Robots.txt در سئو سایت
فایل Robots.txt یکی از مهم ترین راه های کنترل رفتار خزنده های وب هستند. اگر از دستورالعمل هایی استفاده کنید که محدودیت های زیاد و بیهوده ای را در دسترسی به وبسایت ایجاد کنند، احتمال اینکه وبسایت شما سهم خود را در نتایج جستجو از دست بدهد، بالاتر می رود.
از طرف دیگر، اگر بتوانید با دستورالعمل های درست و به جا از خزش و ایندکس صفحات تکراری، غیرضروری و بی کیفیت وبسایت خود جلوگیری کنید و شرایط لازم برای ایندکس صفحات مهم وبسایت خود را فراهم کنید، احتمال ارتقا رتبه بندی سایت شما افزایش پیدا می کند.
در اصل، وجود یک فایل ربات تاثیر مستقیمی در سئو سایت ندارد بلکه این قوانین و دستورالعمل های موجود در این فایل هستند که تعیین کننده رفتار خزنده ها و در نتیجه، نحوه ایندکس شدن سایت هستند. پس اگر دستورات مهمی مثل disallow را به دقت و به صورت هوشمندانه لحاظ کنید، می توانید مطمئن باشید که در کنار صرفه جویی در بودجه خزش، قسمت های مهم وبسایت شما توسط ربات ها خزیده و ایندکس می شود و در نتیجه در اختیار کاربران قرار می گیرند. کاربران راضی و خوشحال، یکی از مهم ترین نیازمندی های ارتقا رتبه بندی یک وبسایت هستند.
نکات مهم در مورد فایل robots
با استفاده از نکات زیر می توانید یک فایل Robots.txt درست و ایده آل ایجاد کنید:
- موقع نوشتن دستورات، هر دستور را در خطوط جدا بنویسید.
روش بد:
User-agent: * Disallow: /directory/ Disallow: /another-directory/روش خوب:
User-agent: *
Disallow: /directory/
Disallow: /another-directory/- برای ساده سازی دستورالعمل ها از وایلد کارت هایی مثل * و $ استفاده کنید.
- سعی کنید برای فایل ربات سایت خود، کامنت قرار دهید تا توسعه دهندگان و حتی خود شما هم در آینده از این کامنت ها کمک بگیرید. برای کامنت گذاری در فایل Robots.txt می توانید از کاراکتر # استفاده کنید.
# This instructs Bing not to crawl our site.
User-agent: Bingbot
Disallow: /- فایل های جاوا اسکریپت و CSS سایت خود را با فایل ربات مسدود نکنید چون اگر ربات ها به این محتوا دسترسی نداشته باشند، ممکن است محتوای وبسایت شما به درستی به کاربران ارائه نشود.
- حتماً لینک مربوط به نقشه سایت خود را در فایل ربات قرار دهید تا ربات ها مسیر واضح تری را طی کنند.
- هنگام استفاده از wild card هایی مثل * و $ مراقب باشید چون استفاده نادرست از آنها می تواند باعث مسدود شدن کل وبسایت شود.
- برای مسدود کردن محتوای خصوصی خود از robots.txt استفاده نکنید. به عنوان مثال اگر می خواهید صفحه حاوی اطلاعات خصوصی کاربر را مسدود کنید، بهتر است از روش های دیگری مثل رمز عبور یا متا تگ noindex استفاده کنید. از طرف دیگر، لینک مربوط به صفحه خصوصی که در فایل ربات قرار می دهید، در دسترس عموم قرار می گیرد و این باعث فاش شدن لوکیشن محتوای خصوصی وبسایت شما می شود.
- اگر صفحات وبسایت خود را طوری طراحی کرده اید که پیوندهای زیادی همراه متن انکر توصیفی به صفحه مسدود شده وجود دارد، قانون disallow صفحه موردنظر که در فایل ربات قرار داده اید، کار نمی کند چون خزنده ها با استفاده از این لینک ها می توانند آن را هم ایندکس کنند. اگر می خواهید از این مسئله جلوگیری کنید، باید از تگ Meta Robots یا هدر X-Robots-Tag استفاده کنید.
- موتورهای جستجو، محتوای فایل ربات ها را کش می کنند اما معمولاً این داده های کش شده به صورت یک بار در روز آپدیت می شود. پس اگر می خواهید این فایل را تغییر دهید و این فایل کش شده را سریع تر آپدیت کنید، می توانید URL فایل ربات را به گوگل ارسال کنید.
- حداکثر اندازه ای که گوگل برای فایل ربات لحاظ کرده است، 521 کیلوبایت است و اگر اندازه فایل ربات شما بیشتر از 521 کیلوبایت باشد، احتمال نادیده گرفتن آن بالا می رود.
- تاثیر فایل ربات در عملکرد وبسایت و رتبه بندی موتورهای جستجو را نظارت کنید.
- بعد از هر تغییر یا تکمیل ساختار وبسایت خود، محتوای فایل ربات را هم آپدیت کنید.
- تجربه کاربری را در اولویت قرار دهید و قوانین را طوری تنظیم کنید که با استراتژی محتوای وبسایت مطابقت داشته باشند.
سخن آخر
فایل Robots.txt یک راهکار عالی برای کنترل رفتار ربات های خزنده وب است که با استفاده از آن می توانید از نمایش محتوای تکراری و غیرضروری سایت خود در نتایج جستجو جلوگیری کنید و در کنار صرفه جویی در بودجه خزش، ارزش محتوای مهم وبسایت را به طور واضح برای خزنده ها مشخص کنید. ما سعی کردیم در این مقاله تمام اطلاعات لازم برای نحوه ایجاد فایل Robots.txt و نحوه استفاده درست از دستورالعمل های مربوط به این فایل را به طور مفصل توضیح دهیم. امیدواریم با استفاده از این مطالب بتوانید یک فایل ربات عالی ایجاد کنید که تاثیر خوبی در عملکرد وبسایت شما داشته باشد.
از اینکه تا انتهای مقاله با ما همراه بودید، از شما متشکریم. امیدواریم که مطالعه این مقاله برای شما مفید واقع شده باشد. در صورت داشتن هرگونه سوال، درخواست و نیاز به راهنمایی، می توانید با ثبت نظر خود، با ما وارد ارتباط شوید تا هر چه زودتر به شما پاسخ دهیم.




