




دستور cut در لینوکس + کاربردهای پیشرفته
اگر به دنبال ابزاری برای پردازش فایل های متنی هستید تا کارهایی مثل استخراج خطوط یا محتوای خاص را انجام دهید، می توانید با خیال راحت به دستور cut در لینوکس اعتماد کنید.
ابزار cut یکی از ابزارهای پیش فرض لینوکس است که برای برش دادن بخش های خاص از هر خط فایل متنی ساختاریافته مثل csv استفاده می شود و این آپشن ها هستند که تعیین کننده رفتار دستور cut هستند.
پیش نیازهای دستور cut در لینوکس
- سیستم یا سرور لینوکس
- دسترسی به ترمینال
- اطلاع از ساختار فایل متنی موردنظر
* برای تهیه یک سرور لینوکس امن و قدرتمند می توانید به صفحه خرید سرور مجازی لینوکس مراجعه کنید.
نصب ابزار cut در توزیع های لینوکس
با اینکه ابزار cut یکی از پیش فرض های تمام توزیع های لینوکس است ولی اگر موقع اجرای آن با خطای not found روبرو شدید، حتماً باید نسبت به نصب پکیج coreutils اقدام کنید.
توزیع های مبتنی بر دبیان مثل اوبونتو
sudo apt-get install coreutilsتوزیع های مبتنی بر RedHat مثل Centos و فدورا
sudo yum install coreutils
یا
sudo dnf install coreutilsتوزیع های مبتنی بر آرچ لینوکس مثل مانجارو
sudo pacman -S coreutilsبعد از اینکه دستور نصب cut را اجرا کردید، با دستور زیر می توانید از وضعیت نصب آن مطمئن شوید:
cut --versionبا دیدن نسخه ابزار cut می توانید مطمئن شود که این ابزار به درستی نصب شده است و می توانید از آن استفاده کنید.
سینتکس و آپشن های دستور cut در لینوکس
سینتکس پایه دستور cut به صورت زیر است:
cut [options] [file]Options
برای اینکه رفتار یا در واقع مسئولیت دستور cut را مشخص کنید، حتماً باید آپشن های مناسبی را در دستور لحاظ کنید در غیر این صورت خروجی دستور با ارور همراه خواهد شد.
File
در این بخش باید اسم فایلی که می خواهید پردازش کنید را وارد کنید که در صورت نیاز می توانید اسم چند فایل را هم وارد کنید. دستور cut خروجی مربوط به این فایل ها را با هم نشان می دهد.
آپشن های دستور cut
| آپشن | کاربرد |
| f- یا fileds– | جداسازی خطوط فایل بر اساس یک یا چند فیلد (رایج ترین آپشن) |
| b- یا bytes– | جداسازی خطوط فایل بر اساس یک یا چند بایت |
| c- یا characters– | جداسازی خطوط فایل بر اساس یک یا چند کاراکتر |
| d- یا delimiter– | تعیین جداکننده به جای جداکننده پیش فرض cut یعنی Tab |
| output-delimiter– | تعیین جداکننده خروجی |
| complement– | انتخاب بایت، کاراکتر یا فیلد خاص برای عدم نمایش در خروجی |
| s- یا only-delimited– | عدم نمایش خطوط فاقد جداکننده در خروجی |
شاید تا الان کاربرد و نحوه استفاده از دستور cut کمی برایتان گنگ باشد ولی با تست مثال های کاربردی که در ادامه بررسی می کنیم، می تواند درک واضحی از وظیفه این دستور به دست بیاورید.
مثال های کاربردی از دستور cut در لینوکس
مثال های cut را از ساده تا پیشرفته مرتب کرده ایم تا با انواع کاربردهای این دستور فوق العاده آشنا شوید:
استخراج فیلدهای موردنظر از خطوط متن
برای اینکه خطوط موجود در فایل متنی را با استفاده از یک یا چند فیلد برش دهید و در خروجی نشان دهید، باید آپشن f را در دستور لحاظ کنید.
فرض کنید فایل متنی file.txt ما به صورت زیر است و فیلدهای آن طبق جداکننده پیش فرض یعنی tab جدا شده اند :
Name Age Department
John Smith 36 HR
John Wayne 48 Finance
Edward King 40 Finance
Stephen Fry 50 ITاگر بخواهید فیلد اول را در خروجی ببینید، باید دستور cut را به صورت زیر اجرا کنید:
cut -f 1 file.txt 
حالا اگر می خواهید فیلدهای اول و سوم را در خروجی ببینید، باید دستور زیر را اجرا کنید:
cut -f 1,3 file.txt  اگر تعداد فیلدها زیاد باشد، برای اینکه محدوده خاصی را برای فیلتر سازی در نظر بگیرید، مثلاً از فیلد اول تا فیلد ۴ ام را در خروجی ببینید، باید دستور زیر را اجرا کنید:
اگر تعداد فیلدها زیاد باشد، برای اینکه محدوده خاصی را برای فیلتر سازی در نظر بگیرید، مثلاً از فیلد اول تا فیلد ۴ ام را در خروجی ببینید، باید دستور زیر را اجرا کنید:
cut -f -4 file.txt یا بر عکس، برای بررسی فیلد چهارم تا آخر، می توانید از دستور زیر استفاده کنید:
cut -f 4- file.txt یا اگر بازه خاصی را برای فیلدها در نظر دارید می توانید از nامین تا mامین فیلد را در خروجی ببینید:
cut -f 4-8 file.txt برش خطوط فایل متنی بر اساس شماره بایت
اگر می خواهید به بایت های خاصی از خطوط موجود در فایل متنی دسترسی پیدا کنید، باید از آپشن b استفاده کنید.
اگر همان فایل قبلی را در نظر بگیرید:
Name Age Department
John Smith 36 HR
John Wayne 48 Finance
Edward King 40 Finance
Stephen Fry 50 ITبرای اینکه بایت سوم هر یک از خطوط را در خروجی ببینید، باید از دستور زیر استفاده کنید:
cut -b 3 file.txt اگر از ابتدای خط، شروع به شمارش بایت ها کنید، می بینید که بایت سوم هر خط همان بایت هایی است هستند که در خروجی می بینید. مثلاً اگر Name را در نظر بگیرید، بایت اول (N)، بایت دوم (a) و بایت سوم m است.
اگر از ابتدای خط، شروع به شمارش بایت ها کنید، می بینید که بایت سوم هر خط همان بایت هایی است هستند که در خروجی می بینید. مثلاً اگر Name را در نظر بگیرید، بایت اول (N)، بایت دوم (a) و بایت سوم m است.
برای اینکه چند بایت را لحاظ کنید، باید دستور cut را به صورت زیر اجرا کنید:
cut -b 1,2,3 file.txt برای تعیین یک بازه خاص از بایت ها، باید از خط تیره (-) استفاده کنید:
برای تعیین یک بازه خاص از بایت ها، باید از خط تیره (-) استفاده کنید:
cut -b 1-5 file.txt اگر می خواهید دو بازه را مشخص کنید، باید از دستور زیر استفاده کنید:
اگر می خواهید دو بازه را مشخص کنید، باید از دستور زیر استفاده کنید:
cut -b 1-5,7-10 file.txtاگر شماره بایت خاصی را در نظر دارید و دوست دارید از اول خط تا آن شماره بایت را در خروجی ببینید، باید دستور را به صورت زیر اجرا کنید:
cut -b -11 file.txtبرای مشاهده بایت ها از یک بایت خاص تا آخر هم باید دستور cut را به صورت زیر اجرا کنید:
cut -b 11- file.txtکات کردن خطوط بر اساس شماره کاراکتر
برای برش دادن خطوط متن بر اساس کاراکتر می توانید از آپشن c استفاده کنید.
برای اینکه کاراکتر چهارم فایل متنی file.txt را برش دهیم و در خروجی نشان دهیم، باید از دستور زیر استفاده کنید:
cut -c 4 file.txt برای نمایش چند کاراکتر از خطوط فایل هم می توانید از دستور زیر استفاده کنید:
برای نمایش چند کاراکتر از خطوط فایل هم می توانید از دستور زیر استفاده کنید:
cut -c 1,5,7 file.txtبرای مشاهده یک سری متوالی از کاراکترها هم کافیست از خط تیره استفاده کنید:
cut -c 3-5 file.txtجهت مشاهده کاراکتر اول تا چهارم می توانید از دستور زیر استفاده کنید:
cut -c -4 file.txtکاراکتر چهارم تا آخر، هم با دستور زیر قابل مشاهده است:
cut -c 4- file.txtشاید فکر می کنید که آپشن b و c کاربرد یکسانی دارد و عملاً وظیفه مشابهی دارند.
بله درست است. زمانی که در فایل متنی موردنظر شما از رمزگذاری تک بایتی مثل ASCII استفاده شده باشد، کاربرد این دو آپشن یکسان است.
اما اگر فایل متنی شما حاوی کاراکترهای غیرانگلیسی مثل فارسی و عربی باشد، قضیه فرق می کند چون بعضی از کاراکترهای مربوط به این زبان ها بیش از یک بایت هستند و در شمارش بایت ها و کاراکترها اختلاف وجود خواهد داشت.
مثلاً اگر فایل متنی شما حاوی متن “سلام خوبی؟” باشد، خروجی مربوط به بازه اول تا ۹ ام با آپشن c و b متفاوت خواهد بود:
پس بهتر است نوع کد گذاری و تعداد بایت های هر کاراکتر زبان موردنظر را در نظر بگیرید و سپس بر اساس آن، آپشن b یا c را انتخاب کنید.
تعیین جداکننده برای برش خطوط فایل متنی بر اساس فیلد
اگر فرمت فایل موردنظر شما جور متفاوتی است و فیلدهای با یک جداکننده دیگری (به جز tab) جدا شده اند، با استفاده از آپشن d می توانید نوع جداکننده را مشخص کنید تا عملیات برش با به درستی انجام شوند.
به عنوان مثال یک فایل متنی csv را در نظر بگیرید:
Name,Age,City
Alice,30,New York
Bob,25,Los Angeles
Charlie,35,Chicago
David,40,Houston
Eve,22,San Franciscoمی بینید که فیلدهای آن بر اساس , جدا شده اند و اگر بیایید دستور زیر را برای آن اجرا کنید، به خروجی مطلوب نخواهید رسید:
cut -f 1,3 file.txt حالا اگر بیایید جداکننده را مشخص کنید، این پروسه برش با دقت بیشتری انجام خواهد شد:
حالا اگر بیایید جداکننده را مشخص کنید، این پروسه برش با دقت بیشتری انجام خواهد شد:
cut -d ',' -f 1,3 یک مثال کاربردی تر دیگر هم بررسی می کنیم:
یک مثال کاربردی تر دیگر هم بررسی می کنیم:
فرض کنید می خواهید فیلدهای نام کاربری (1) و دایرکتوری محلی (6) مربوط به آن از فایل etc/passwd/ برش دهید. 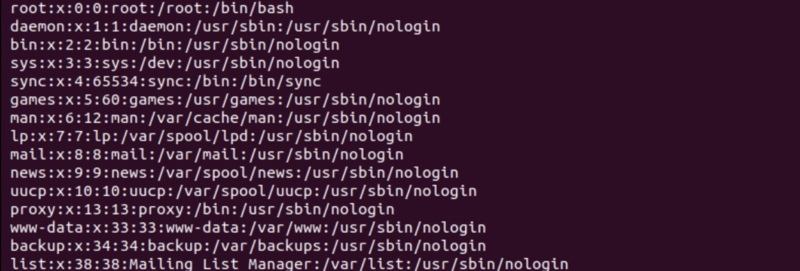
می بینید که جداکننده آن : است. حالا برای اینکه به هدف خود برسید باید دستور cut را به صورت زیر اجرا کنید:
cut -d ':' -f 1,6این آپشن تعیین جداکننده برای زمانی است که می خواهید خطوط را بر اساس فیلدها برش دهید چون فقط فیلدها هستند که به جداکننده ها اهمیت می دهند. آپشن های c و b، جداکننده را هم یک بایت یا کاراکتر در نظر می گیرند و در شمارش لحاظ می کنند.
عدم نمایش فیلد، بایت یا کاراکتر خاص در خروجی cut
تا الان سعی داشتیم، فیلدها یا بایت هایی که می خواهیم را در خروجی ببینیم ولی اگر بخواهیم فیلد، کارکتر یا بایت خاصی را نادیده بگیریم و به غیر از آن، تمام محتوای خطوط را مشاهده کنیم، باید از آپشن complement استفاده کنیم.
به عنوان مثال، اگر فایل زیر را در نظر بگیرید:
ID Name Age City Occupation Salary
1 John Doe 28 New York Engineer 85000
2 Jane Smith 34 Los Angeles Designer 92000
3 Michael Brown 41 Chicago Manager 105000
4 Emily Davis 22 San Francisco Developer 80000برای اینکه تمام فیلدها به جز فیلد Age را از متن بالا برش دهید، باید دستور زیر را اجرا کنید:
cut -f 3 file.txt --complementهمین سینتکس برای بایت ها و کاراکترهای موردنظر هم صدق می کند. کافیست آن ها را در دستور لحاظ کنید و در انتها هم complement را اضافه کنید تا تمام کاراکترها و بایت ها به جز موارد مشخص شده را در خروجی ببینید.
تعیین یک جداکننده برای خروجی
وقتی فایل متنی موردنظر را بر اساس چند فیلد/کاراکتر/بایت برش می دهید، دستور cut، خروجی مربوط به آن را بدون هیچ جداکننده خاص به هم وصل می کند.
حالا اگر می خواهید جدا کننده خاصی مثل (_) را برای فیلدها، بایت ها یا کاراکترهای خروجی در نظر بگیرید، کافیست آن را با آپشن output-delimiter– مشخص کنید:
cut -f 1,3 file.txt --output-delimiter='_'
cut -b 1-5,6-10 file.txt --output-delimiter='_'
cut -c 1-5,6-10 file.txt --output-delimiter='_'تا اینجا کاربردهای پایه دستور cut را بررسی کردیم اما در دنیای لینوکس، این توانایی را دارید که خروجی و ورودی دستورات را به هم پایپ کنید و قابلیت های هر کدام از دستورات را ارتقا دهید.
ترکیب دستور cut با grep
کاربرد دستورات پایه لینوکس به سطح تخیل شما بستگی دارد و کافیست سناریوهایی که در ذهن دارید را با ترکیب دستورات متنوع، وارد عمل کنید که cut هم از این قائده مستثنی نیست.
به عنوان مثال فرض کنید فایل متنی زیر را دارید:
ID Name Age City Occupation Salary
1 John Doe 28 New York Engineer 85000
2 Jane Smith 34 Los Angeles Designer 92000
3 Michael Brown 41 New York Engineer 105000
4 Emily Davis 22 San Francisco Developer 80000
5 Chris Wilson 30 Houston Analyst 78000
6 Sarah Johnson 27 Austin Teacher 60000حالا می خواهید تمام مهندسانی (Engineer) که نیویورک زندگی می کنند را استخراج کرده و فقط اسم و حقوق آن را در خروجی ببینید.
برای اینکه باید خطوط حاوی Engineer و New York را با دستور grep استخراج کنید:
grep "Engineer" employees.txt | grep "New York"سپس خروجی آن را با دستور cut پایپ کنید و فقط فیلدهای ۲ و ۶ که مربوط به اسم و حقوق است را از آن برش داده و در خروجی نمایش دهید:
grep "Engineer" employees.txt | grep "New York" | cut -f 2,6سخن آخر
دستور cut یکی از ابزارهای عالی برای پردازش فایل های متنی در لینوکس است که اگر با سینتکس و آپشن های آن آشنا شوید می توانید از آن برای برش دادن بخش های دلخواه از فایل متنی خود استفاده کنید و تجزیه و تحلیل های لازم را انجام دهید.




